実務家がMaterials Informaticsに期待すること「第5章:実務での活用戦略」

これまでの振り返り
これまでの4つの章では、MIが持つ本質的な特徴、そして強みと弱み、そして実務で直面する技術的・組織的な制約について詳しく考察してきました。
-
第1章では、MIがデータから法則を見出し、予測や最適化を行う能力を持つこと、そしてデータの範囲外の予測には注意が必要であることを示しました。
-
第2章では、MIとシミュレーションを比較し、MIが「汎用的なツール」として、多岐にわたる複雑な問題に柔軟に対応できることを確認しました。
-
第3章では、MIの進化が「異なる要素をつなぐ」ことにあると述べ、技術間・部門間の連携を強化する価値を強調しました。
-
第4章では、MIを実務で活用する上で不可欠なデータの品と量、相関関係と因果関係の違い、そして組織的な壁といった現実的な制約に焦点を当てました。
この最終章では、これらの知見を統合し、実務家がMIを導入し、最大限活用するための具体的な戦略を提示します。
1. MI導入の第一歩:スモールスタートで成功体験を積む
MIの導入を成功させるには、最初から大規模なシステムを構築するのではなく、小さく始めて成果を出すことが最も重要です。
1.1 具体的な導入ステップ
-
課題の特定:まず、MIで解決したい具体的な課題を明確にします。「実験回数を減らしたい」「特定の材料特性を予測したい」など、スコープを絞り込みましょう。具体的であればあるほど望ましいです。
-
データの準備:特定した課題に関連する既存のデータを集めます。この段階で、データの品質(バイアス、エラーなど)や量を確認し、MIの適用可能性を評価します。この時、データ収集に要する時間も考慮してください。例えば、一般的によい予測モデルを作るために説明変数の数を増やすことは良いことですが、そのようなデータを準備するだけで半年を要するようではスモールスタートとは言い難くなります。
-
モデルの構築と検証:収集したデータを用いてモデルを構築し、予測精度を検証します。この際、第1章で述べたように、学習データの範囲内で予測精度がどの程度かを確認します。
-
成果の可視化と共有:得られた成果(例:予測精度の向上、実験回数の削減)を社内で共有します。これにより、MIに対する理解と期待を高め、次のステップへの理解を引き出しやすくなります。
このアプローチは、第2章で述べたMIの「気軽に利用出来る汎用的手法」としての特徴を最大限に活かすものです。

図1: MI導入の基本的なステップ。
2. データ中心の戦略を確立する
第4章で述べたように、データの質と量がMIの成否を分ける最大の要因です。MIの導入は、同時に「データ中心の文化」を醸成する機会でもあります。
2.1 属人的知識の形式知化
-
第1章でも強調したように、失われやすい属人的知識をデジタル化し、MIに活用することは経営課題の一つです。職人の「勘」や「経験」を、適切なセンサーデータや定性体的な評価基準として体系的に記録する仕組みを構築します。その際に最も大切なことは、属人的知識を持つ人物への尊厳を最大限尊重し、その人物と協力体制を構築することです。上から目線は厳禁です。
-
これにより、個人の知識が組織全体の試算となり、第3章で述べた「知識の蓄積と活用」が実現します。
2.2 継続的なデータ品質管理
第3章で提示したデータ品質の課題を解決するため、以下の取り組みが不可欠です。
-
データ入力ルールの統一:データの種類ごとに、記録すべき項目とフォーマットを標準化します。ただし、実験は、ほとんどの試行が前回とは異なる内容について行われるものであり、フォーマットの統一が難しいと感じることが多いのも事実です。従って、同じフォーマットを適用する領域(テーマ)を広く取り過ぎず、適切な領域にとどめておくことも重要です。また、自由度が高いグラフ形式のフォーマットを採用することを考えてもよいでしょう。
-
品質チェックの自動化:必須項目の欠損チェックや値の範囲チェックなど、入力時の自動チェック機能を導入するとよいでしょう。
-
メタデータの管理:データの来歴(誰が、いつ、どのように取得したか)を追跡可能にすることで、データの信頼性と完全性を高めます。また、テーマ番号、実験番号など、実験の追跡に必要な情報もメタデータとして統一的に管理することも有効です。

図2: 属人的知識を形式知化し、組織の知に高めるプロセスを示した図。
3. 組織的の壁を超える
MIは、部門や技術間の「つなぎ役」として真価を発揮します。第3章で述べた知識のサイロ化を克服ための戦略を以下に示します。
3.1 知識の統合を促進するプラットフォーム
-
異なるフォーマットで分散しているデータを統合するため、第3章で提示したFAIR原則(Finable, Accessible, Interperable, Reusable)に基づいたデータプラットフォームを構築します。
-
構造化データだけではなく、考察文やメモ書きのような非構造化データもなるべく保存しておく
-
これにより、研究者や技術者が自身の専門分野を超えて、他部門のデータを容易に活用できるようになり、予期せぬ発見や新たな連携が生まれる可能性が高まります。
3.2 既存技術とのハイブリッド活用
MIは、既存技術を置き換えるものではなく、補完し、その価値を最大化するツールです。
-
シミュレーションとの連携:第2章で述べたように、シミュレーションが有効な場面ではシミュレーションを使い、MIはシミュレーションが苦手とする複雑な系や多目的変数の予測で活躍します。第3章で紹介した事例のように、両者を統合することで、より高精度な予測や効率的な材料探索が可能になります。
-
ハイスループット実験との連携:第3章で紹介したように、MIをハイスループット実験と組み合わせることで、「AIが次の実験を提案し、システムが実行する」という自律的な研究サイクルを実現できます。だたし、現在の技術では、どんな内容の検討にもハイスループット実験が適用できるわけではありません。基本的にはプロセスが固定された合成条件や配合条件検討で威力を発揮しますので、このような検討には積極的に活用してください。
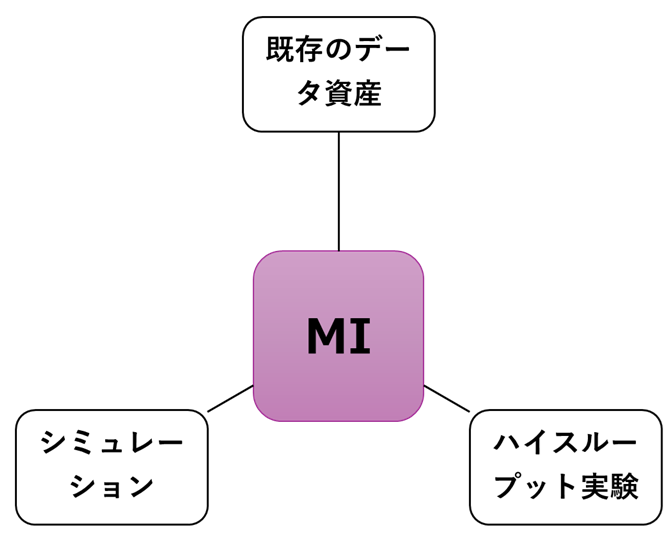
図3: MIをハブとしたハイブリッド開発プラットフォームの連携図。
4. まとめと今後の展望
これまでの5つの章を通じて、「MIは何ができるのか?」という問いに答えるべく、その本質、強みと弱み、そして実務での活用戦略について考察してきました。
- MIは、データに基づいた予測、最適化、そして知識統合を通じて、材料開発を効率化し、新たな発見を促す強力なツールです
- しかし、その能力はデータの質と量に依存し、因果関係の特定や学習範囲外の予測には限界があることを理解しておく必要があります
- MIの成功は、技術的な導入だけではなく、データ品質の管理、組織間の連携、そして属人的知識の形式知化といった戦略的な取り組みにかかっています
材料開発の現場では、技術の進歩に伴い、個人が扱える知識量を超えた複雑な課題が増えています。MIは、この課題を乗り越え、組織全体の知識を統合し、効率的な開発を推進するためのカギとなります。今後、さらに高度なアルゴリズムやデータ共有の仕組みが発展することで、MIは材料開発における「戦略的な武器」として、その重要性を一層増していくでしょう。
最後に
このシリーズが、読者の皆様がそれぞれの立場で、「MIは何ができるのか?」という問いへの答えを見つけ、MIを実務で活用する第一歩を踏み出すきっかけとなれば幸いです。