第5回:VibLog: 純粋なVibe Codingの限界。ARIAのための高純度燃料精製と、15円で完結する論文抽出パイプラインの泥臭い現実

1.VibLogを「次」のフェーズへ
なぜVibLogのアップデートが必要なのか
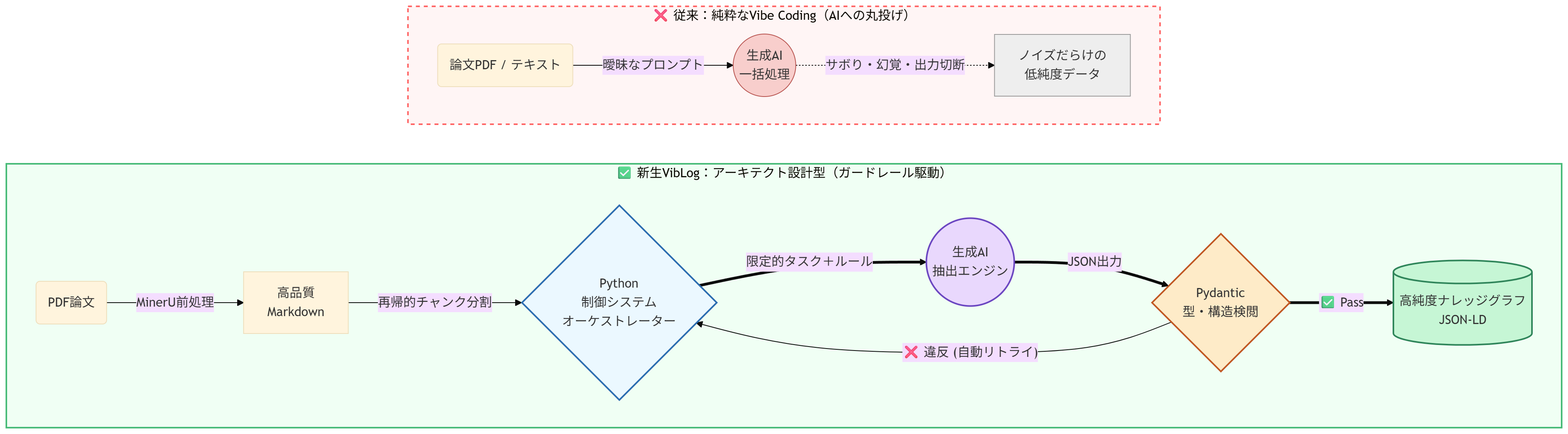
これまでのVibLogで実践してきた「すべてをVibe的に(生成AIに丸投げで)進めるやり方」の限界を告白します。
今シリーズの目的は、ARIAが実際の開発現場で使えるツールなのかを検証することです。 「5報の論文情報とVibe Codingをフル活用する」という戦略を掲げ、目的の速やかな達成に邁進してきました。その結果、前回までのブログでお伝えした通り、「ARIAは実践で使える可能性が高いツールである」との感触を得ましたが、明確な結論を出すにはさらなる検証が必要との見解に至りました。
今後の検証ポイントは以下の2点です。
- ナレッジグラフの情報量を増やす(5報 → 100報)
- 拡張したナレッジグラフを用いて、ARIAの優雅な劣化(例えば、ドメインを跨ぐ推論がどの程度機能するのか、その拡張性はどの程度コントロールできるのか)を検証する
一方、この先も「すべてをVibe的に(生成AIに丸投げで)進めるやり方」では行き詰まることが明確になりました。理由は以下の通りです。
- ナレッジグラフ自動作成をスケール(大規模化)する操作には不向きである
- 事実に基づくARIAの「厳格な作動原理」と、Vibe的に(その時の気分で)結果の味付けを変える「生成AIの性質」との相性が悪い
ARIA(自律的推論AI)を駆動させるためには、ノイズのない「高純度なデータ燃料」が大量に必要です。しかし、AIの自由奔放な生成に任せていると、出力が安定せずパイプラインがすぐ崩壊してしまいます。これらを修正し、強固な基盤を作ることが今回のVibLogアップデートの主な目標です。
VibLogアップデート戦略
やるべきことは単純明快です。「生成AIが得意な処理」と「プログラミングが得意な処理」を区別し、VibLogパイプラインを再構築することです。
現時点での生成AIの弱点は以下の通りです。
- 処理しなければならない情報量が増えるほど「手抜きやおさぼり」しやすくなり、それをごまかすために「ウソの情報を捏造(ハルシネーション)する頻度」が高くなる
- 常に同じ結果を返す「確定的な処理」ではなく、実行のたびに揺らぐ「確率的な処理」となる
そこで本アップデートでは、以下の4点を実施しました。
- ナレッジグラフ抽出処理フローのPythonコード化:必ず同じ処理フローでの実施・検証が保証されるよう、生成AIはPythonコードから呼び出される形で「既定の処理結果のみを返却する部品」として扱う。
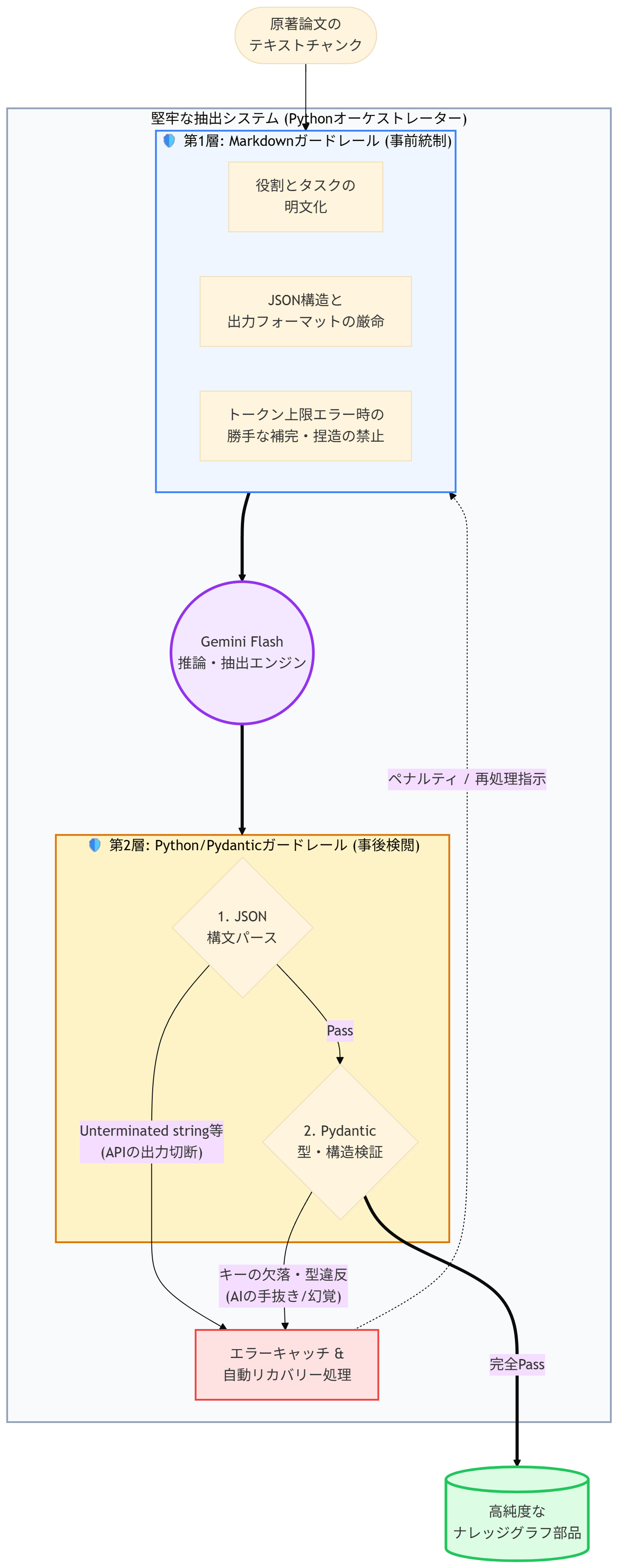
- 生成AIの利用場面の限定:全体の処理フローをPythonコードに集約することで、生成AIが得意とする「論文からナレッジ(PSP)抽出」「抽出ナレッジの正規化の補助」「ARIA出力結果のとりまとめ」のみのタスクを限定する。 3.「2段階の強力なガードレール」設置:①Pythonコードによる厳格な検閲機構、②Markdownファイルでの「役割」「タスク」「禁止事項」の明文化。
- 論文ファイルの前処理導入:MinerUを用いて、PDFから高品位なMarkdownファイルを生成する前処理を新設。
結果として、「人間が読めば数時間かかる半導体パッケージング論文の因果関係抽出を、1時間・わずか15円のAPIコストで900ノードのグラフに変換する」という驚異的な成果を叩き出すことに成功しました。
次章からは、新生VibLogのカギとなる「ガードレール」設計の裏話を中心にお伝えします。
2.アプローチの転換:AIを制御する「ガードレール」の設計
Pythonで処理フロー全体を規定したことにより、生成AIが記憶しておくべき情報量を大きく圧縮できました。これだけでも生成AIが「手抜きやおさぼり」をしにくい土壌に変わっています。
しかし、「論文からナレッジ(PSP)を抽出する」「抽出したナレッジを正規化する」といった作業を高精度で実施するためには、依然として大量の情報を保持しなくてはいけません。論文の内容によって、文章の長さ、複雑さはまちまちです。高難易度の論文処理を完全にAI任せにすると、確実に巧妙な手抜きを行います。
そこで重要な役割を果たすのが、AIに強力な行動制限を課す「ガードレール」であり、その設計こそが新生VibLog成功のカギを握っています。
手法の進化:アーキテクトによるガードレール設計
これまで通り、Roo Code等のエージェントを使い、可能な限りVibe的に(対話を通じて)作業を行います。従来との違いは、AIにすべてを「良しなにやっておいて」と頼むのではなく、人間(アーキテクト)が明確な制約(ガードレール)を設計し、それをコーディングやMarkdown形式に落とし込む「実装作業」をAIに担当させる点です。
具体的なガードレール例
-
Pydanticによる厳格な型検証: PSPで規定したJSONの構造を絶対に崩させない「鉄壁のガードレール」の導入
- Pythonコード:Pydanticによるデータ検閲の実施と、型違反発見時の自動リカバリー(再処理)を定義
- Markdownの規制文:規定のJSON構造に合致した結果の返却を厳命
-
再帰的チャンク分割とチェックポイント: トークン通信量制限に伴う途中切断を防ぎ、エラーが起きても中断箇所から確実に再開できる「辞書形式のチェックポイント」機能を確実に実行させるためのガードレール。
- Pythonコード:チャンク分割ルールの規定、トークン上限エラー発生時の再分割ルールの規定、エラー発生時のリカバリー処理の定義
- Markdownの規制文:トークン上限エラー発生時の「勝手な代替処理(捏造など)」の禁止を厳命
Markdownによる規制文(プロンプト)だけにすべてを委ねることはせず、Pythonコード中に強力な検閲機構を組み込み、かつ違反発生時のプロトコルを定義しておく。このような「2層ガードレール構造」をとりいれることこそが、質の高いナレッジグラフを安定して自動生成させる最大のコツです。
また、今回の改修により、将来的に利用する生成AIモデルが変わっても問題が起きないシステム設計になったことも重要です。現在の従量課金制のVertex AIから、軽量なオープンモデルのローカルLLMに乗り換えてコスト削減したり、GoogleだけではなくOpenAIやAntholopicの最新モデルに切り替えて更なる精度向上を目指したりと、柔軟な拡張が可能になっています。
3. ハイライト:LLMパイプライン構築の「泥臭い現実」
ここがエンジニアや研究者の皆様に最も共感していただけるであろう「現場のリアル」です。きれいに自動化できたように見えて、実は裏では様々なトラブルが起こりました。これらのトラブルにより、回収作業は当初の計画よりもかなりの時間がかかりました。読者の皆さんが同じことを経験したときに役に立つよう、包み隠さず内容をお伝えします。
泥臭い現実(1):材料の「破壊」に怯えるAI
テスト用の文章を使った「ガードレール設計」が完了し、いよいよ複数の論文を流し込んで本格抽出開始、ということろで予期せぬ問題が発生しました。
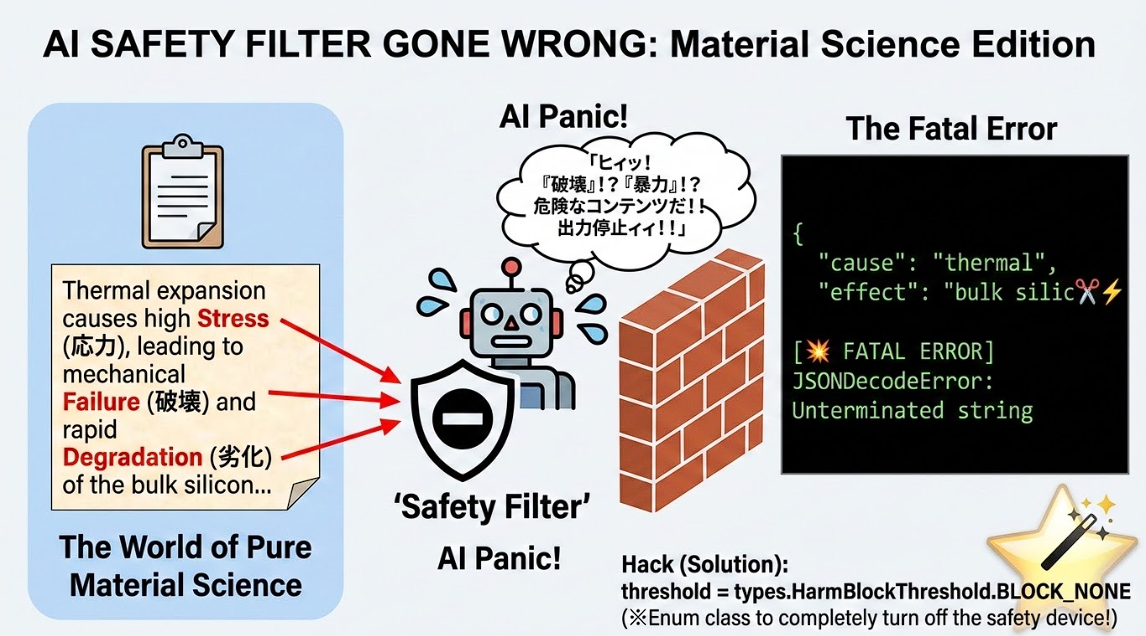
導入したガードレールに関わる「Pydanticの型違反」や「チャンク分割の不具合」を疑って詳しく調査したところ、意外にも「私が危険コンテンツを処理している」というシステムの誤検知が原因でした。
本プロジェクトでは半導体後工程関係の論文を扱っているため、まさか「危険コンテンツ」と判定されるとは夢にも思っていませんでした。実際は、「応力(Stress)」や「破壊(Failure)」といったMI(マテリアルズ・インフォマティクス)特有の学術用語が、APIのセーフティフィルターに「暴力的コンテンツ」として誤検知され、出力が突然物理的に遮断される怪奇現象を引き起こしていたのです。
解決策として選んだのは、SDKの明示的なEnumクラス(BLOCK_NONE)を使って安全装置を完全にオフにするというハックです。一般に広く公開するアプリを開発しているのであれば、システムの安全フィルターを無効化しない方が良いのは言うまでもありませんが、今回はクローズドな個人のプロジェクトということでこの手段を採用しました。
泥臭い現実(2):運用コストの罠
以前もお話ししましたが、今回は個人のプロジェクトであるため「コスパ」を最重要事項として定めています。プロジェクトを開始する前の今年2月、DeepResearchの調査結果をもとにコスパ最強の手段を選択しました。それが、「Google AI Studioの無料特典枠を利用する」という方法でした。
しかし、無料枠のつもりでGemini APIを利用していたら、Googleから突然課金を知らせる連絡メールが届いたのです。Geminiに原因調査を依頼しても「無料枠が使えます」との回答しか返しません。久々に自力で調査した結果、私が当てにしていたGemini APIの無料特典枠は、なんと3月をもって対象外になっていたことが発覚しました。同時に、代替となる「Vertex AIの無料特典」も発見することができ、ほっと一息です。
これまで使っていた「Gemini AI Studio」が主に個人が実証実験的に使うことを想定したものであるのに対し、「Vertex AI」は商用サービスとして生成AIをエンタープライズのアプリに組み込む際に利用することを想定されたものです。コスパ最優先の私としては緊急オペを実施し、Vertex AI APIへの切り替えを完了させました。
今後は無料特典を使い切る勢いで論文からのナレッジグラフ抽出を進めたいと思います。とはいえ、すでに課金されたお金は戻ってきません。生成AI関連のサービスはまさに「日替わりメニュー」です。皆さんも私と同じ失敗をしないよう、最新情報には常に目を光らせておいてください。
泥臭い現実(3):AIの「長い文章を読むふり」問題
最新の生成AIは、数十万文字を一度に読み込める「ロングコンテキスト」を大きなうたい文句にしています。当初はそれを信じて、論文1報を丸ごと一度に処理させようと試みました。しかし、実際には『読める』ことと『細部まで理解して抽出する』ことは全くの別物でした。
情報量が多すぎると、AIは露骨に抽出をサボり(Lost in the Middle現象)、結果がスカスカになったのです。結局、人間が本を読むように、テキストを意味のある段落ごとに分割(チャンク分割)して少しずつ読ませるという、非常に泥臭い『再帰的チャンク分割』の実装が必要でした。
ロングコンテキストモデルだからといって、PDFを丸投げすれば魔法のように構造化されるわけではない、という良い教訓になりました。
4. 結び:人間とAIの新しい協働スタイル
新生VibLogは、これまで通りVibe Codingの良さは活かしつつ、「アーキテクトとしての人間がガードレールを引き、実装を生成AIに任せる」という新しい形で作業を行いました。出来上がったワークフローは、Pythonによる厳格な作業規定と、生成AIが得意な応用作業のコラボレーションにより、極めて高いレジリエンス(回復力)を備えたものに進化しています。
次回予告
次回は、新生VibLogで精製された高純度燃料(JSON-LD)の中身を公開する予定です。「5報」という最小グラフからどのように進化したのかをNeo4j等で可視化し、わかりやすくお伝えしようと思います。そのうえで、その高純度燃料をARIAにどう喰わせて、どのように結果を得るのかという実践編に入っていきます。お楽しみに!